网络原理
关于Kubernetes网络,有如下常见问题
1.Kubernetes的网络模型是什么? 2.Docker背后的网络基础是什么? 3.Docker自身的网络模型和局限 4.Kubernetes的网络组建之间如何通讯 5.外部如何访问Kubernetes集群 6.有哪些开源的组建支持Kubernetes的网络模型
Kubernetes 网络模型
Kubernetes在网络模型设计的一个基础原则是:每个Pod都拥有一个独立的IP地址,而且假定所有Pod都在一个可以直接连通的、扁平的网路空间中。所以不管他们是否运行在同一个Node (宿主机)中,都要求它们可以直接通过对方的IP进行访问。设计这个原则的原因是,用户不需要额外考虑如何建立Pod之间的连接,也不需要考虑将容器端口映射到主机端口等问题。
实际上在Kubernetes的世界里,IP是以Pod为单位进行分配的。一个Pod内部的所有容器共享一个网络堆栈 (实际上就是一个网络命名空间,包括它们的IP地址、网络设备、配置等都是共享的)。按照这个网络原则抽象出来的一个Pod一个IP的设计模型也被IP-Per-Pod模型。
由于Kubernetes的网络模型假设Pod之间访问时使用的是对方的Pod实际地址,所以一个Pod内部的应用程序看到的自己的IP地址和端口与集群内其他Pod看到的一样。它们都是Pod实际分配的IP地址 (从docker0上分配的)。将IP地址和端口在Pod内部和外部保持一致,如果我们可以不使用NAT来进行转换,地址空间也自然是平的。kubernetes的网络之所以这么设计,主要原因就是可以兼容过去的应用。当然,我们使用Linux命令ip addr show 也能看到这些地址,和程序看到的没有什么区别。所以这种IP-per-Pod的方案很好地利用了现有的各种域名解析和发现机制。
一个Pod一个IP的模型还有另外一层含义,那就是同一个Pod内的不同容器将会共享一个网络命名空间,也就是说同一个Linux网络协议栈。这就意味着同一个Pod内的容器可以通过localhost来连接对方的端口。这种关系和同一个vm内的进程之间的关系是一样的,看起来Pod内的容器之间的隔离性降低了,而且Pod内不同容器之间的端口是共享的,没有所谓的私有端口的概念了。如果你的应用必须要使用一些特定的端口范围,那么你也可以为这些应用单独创建一些Pod。反之,对那些没有特殊需要的应用,这样做的好处是Pod内的容器是可以共享部分资源的,通过共享资源互相通信显然更容易和高效。针对这些应用,虽然损失了可接受范围内的部门隔离性,但也是值得的。
IP-per-Pod模式和Docker原生的通过动态端口映射方式实现的多节点访问模式主要区别是后者的动态端口映射会引入端口管理的复杂性,而且访问者看到的IP地址和端口与服务提供者实际绑定的不同 (因为NAT的缘故,它们都被映射成新的地址或端口了),这也会引起应用配置的复杂化。同时,标准的DNS等名字解析服务也不适用了。甚至服务注册和发现机制都将受到挑战,因为在端口映射的情况下,服务自身很难知道自己对外暴露的真实的服务IP和端口。而外部应用也无法通过服务所在容器的私有IP地址和端口来访问服务。
总的来说,IP-per-Pod模型是一个简单的兼容性较好的模型。从该模型的网络的端口分配、域名解析、服务发现、负载均衡、应用配置和迁移等角度来看,Pod都能够被看作一台独立的虚拟机或物理机。
kubernetes集群网络有如下要求
1.所有容器都可以在不用NAT的方式下同别的容器通信
2.所有节点都可以在不用NAT的方式下同所有容器通信
3.容器的地址和看到的地址是同一个
网络模型的要求并没有降低整个网络系统的复杂度。如果你的程序原来的VMware上运行,而使用VMware拥有独立IP,并且它们之间可以直接透明地通讯,那么kubernetes的网络模型就和VMware使用的网络模型是一样的。所以使用这种模式可以很容易地讲已有的应用程序从VMware或物理机迁移到容器上
Docker的网络基础
docker本身的技术依赖于今年Linux内核虚拟化技术的发展,所以Docker对Linux内核的特性有很强的依赖。
Docker使用到的与Linux网络有关的主要技术 (1) Network Namespace (网络命名空间) (2) Veth设备对 (3) Iptables/Nefilter (4) 网桥 (5) 路由
1.网络的命名空间
为了支持网络协议栈的多个实例,Linux在网络栈中引用了网络命名空间(Network Namespace),这些独立的协议栈被隔离到不同的命名空间中。处于不同命名空间的网络栈是完全隔离的,彼此之间无法通讯,就好像两个平行宇宙。通过这种对网络资源的隔离,就能在一个宿主机上虚拟多个不同的网络环境。而docker也正是利用了网络的命名空间特性,实现了不同容器之间网络的隔离。
在Linux的网络命名空间内可以有自己独立的路由表及独立的Iptables/Netfiler 设置来提供包转发、Nat及IP包过滤等功能。
为了隔离出独立的协议栈,需要纳入命名空间的元素有进程、套接字、网络设备等。进程创建的套接字必须属于某个命名空间,套接字的操作也必须在命名空间内进行。同样,网络设备也必须属于某个命名空间。因为网络设备属于公共资源,所以可以通过修改属性实现在命名空间之间移动。当然,是否允许移动和设备的特征有关。
网络命名空间的实现 Linux的网络协议栈是十分复杂的,为了支持独立的协议栈,相关的全局变量都必须修改为协议栈私有。最好的办法就是让这些全局变量成为一个Net Namespace变量的成员,然后协议栈的函数调用加入一个Namespace参数。这就是Linux实现命名空间的核心。
在简历了新的网络命名空间,并将某个进程关联到这个网络命名空间后,就会出现了类似于下图的内核数据结构,所有网站栈变量都放入了网络命名空间的数据结构中。这个命名空间是属于它的进程组私有的,和其他进程组不冲突。
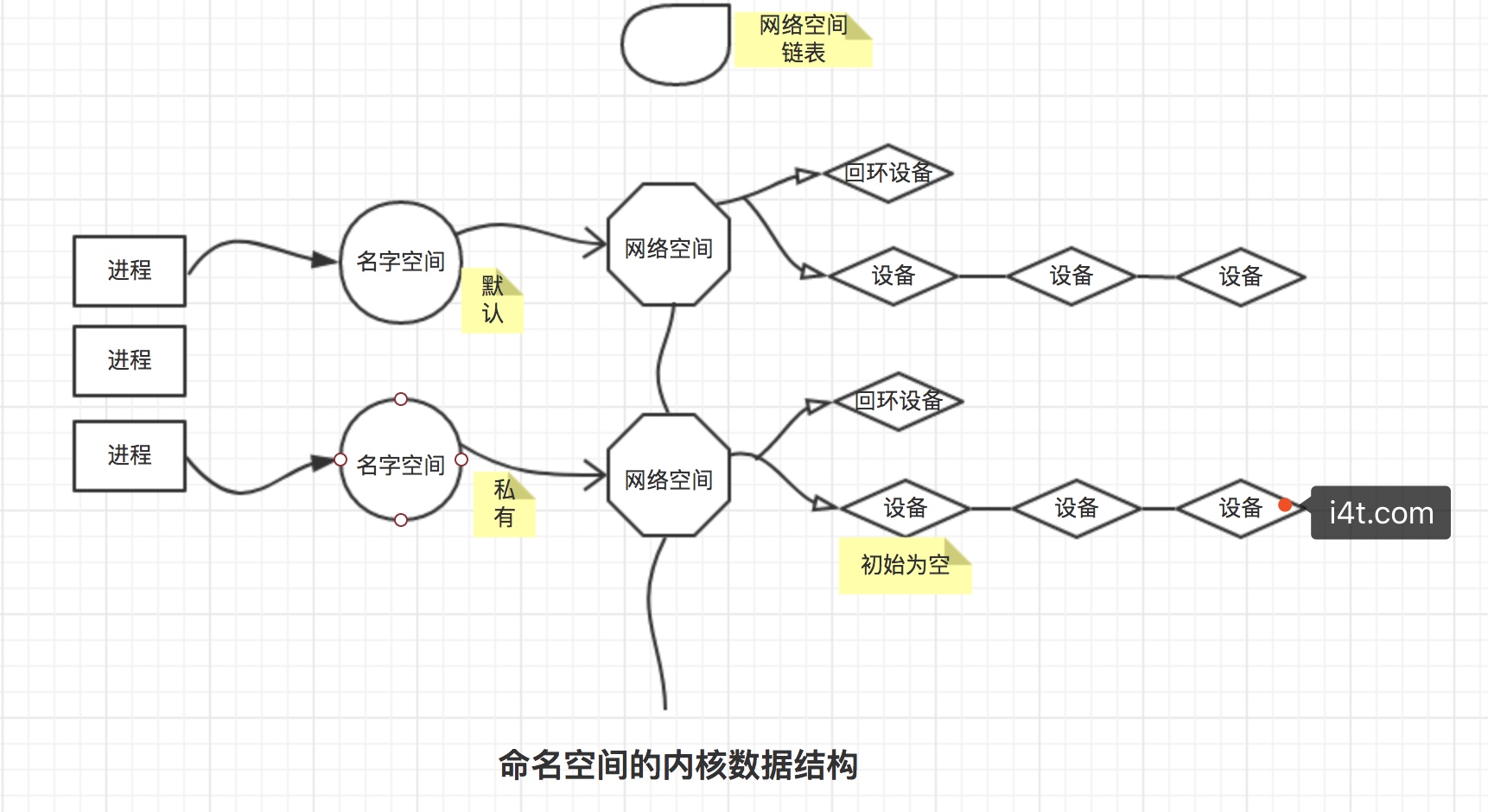 新生成的私有命名空间只有回环lo设备(而且是停止状态),其他设备默认都不存在,如果我们需要,则要一一手工建立。Docker容器中的各类网络栈设备都是Docker Daemon在启动时自动创建和配置的。
新生成的私有命名空间只有回环lo设备(而且是停止状态),其他设备默认都不存在,如果我们需要,则要一一手工建立。Docker容器中的各类网络栈设备都是Docker Daemon在启动时自动创建和配置的。
所有的网络设备(物理的或虚拟接口、桥等在内核里都叫作Net Device)都只能属于一个命名空间,通常物理的设备 (连接实际设备的硬件)只能关系到root这个命名空间中。虚拟的网络设备 (虚拟的以太网接口或者虚拟机网口对)则可以被创建并关联到一个给定的命名空间中,而且可以在这些命名空间中移动。