Kubernetes Heapster监控
Heapster 介绍
目前Heapster已弃用 已弃用:Heapster已弃用。请考虑使用 metrics-server 和第三方指标管道来收集Prometheus格式的指标。有关 支持的更多信息,请参阅弃用时间表。
Github地址:https://github.com/kubernetes/heapster
Kubernetes官方提供了Kubernetes HPA (Horizontal Pod Autoscaling)资源对象。要让我们部署的应用做到自动水平的(水平指的是增减Pod副本数量)进行扩缩容,我们只需要在Kubernetes集群中创建HPA资源对象,然后让该资源对象关联某一需要进行自动扩缩容的应用即可。
HPA默认的是以Pod平均CPU利用率作为度量指标,也就是说,当应用Pod的平均CPU利用率高于设定的阈值时,应用就会增加Pod的数量。CPU利用率的计算公式是:Pod当前CPU的使用量除以它的Pod Request(这个值是在部署deployment时自己设定的)值。而平均CPU利用率指的就是所有Pod的CPU利用率的算术平均值。
Pod平均CPU利用率的计算需要知道每个Pod的CPU使用量,目前是通过查询Heapster扩展组件来得到这个值,所以需要安装部署Heapster。
Hepster 组件介绍
kubernetes有个出名的监控agent—cAdvisor。在每个kubernetes Node上都会运行cAdvisor,它会收集本机以及容器的监控数据cpu,memory,filesystem,network,uptime
在较新的版本中,K8S已经将cAdvisor功能集成到kubelet组件中。每个Node节点可以直接进行web访问
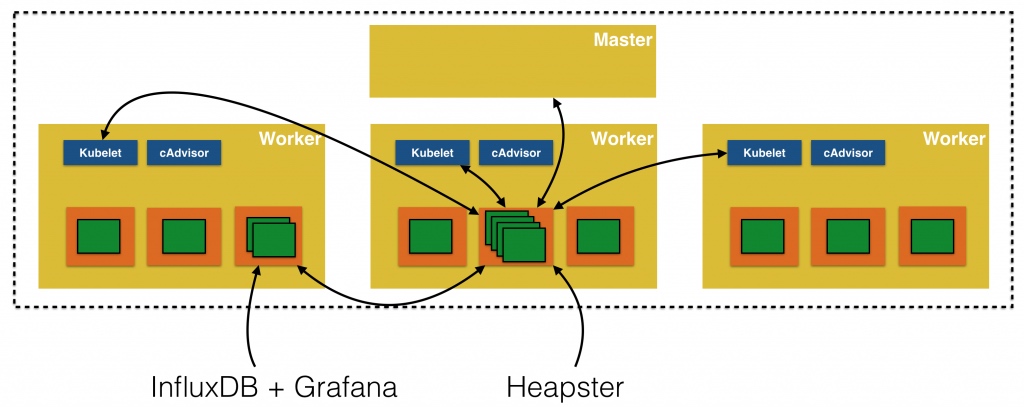
Heapster是一个收集者,将每个Node上的cAdvisor的数据进行汇总,然后导到第三方工具(如InfluxDB)。 Heapster首先从K8S Master获取集群中所有Node的信息,然后通过这些Node上的kubelet获取有用数据,而kubelet本身的数据则是从cAdvisor得到。所有获取到的数据都被推到Heapster配置的后端存储中,并还支持数据的可视化。现在后端存储 + 可视化的方法,如InfluxDB + grafana。
API文档 https://github.com/google/cadvisor/blob/master/docs/api.md
Metrics https://github.com/kubernetes/heapster/blob/master/docs/storage-schema.md
influxdb
influxdb是目前比较流行的时间序列数据库。
何谓时间序列数据库? 什么是时间序列数据库,最简单的定义就是数据格式里包含Timestamp字段的数据,比如某一时间环境的温度,CPU的使用率等。但是,有什么数据不包含Timestamp呢?几乎所有的数据其实都可以打上一个Timestamp字段。时间序列数据的更重要的一个属性是如何去查询它,包括数据的过滤,计算等等。
Influxdb是一个开源的分布式时序、时间和指标数据库,使用go语言编写,无需外部依赖。 它有三大特性:
- 时序性(Time Series):与时间相关的函数的灵活使用(诸如最大、最小、求和等);
- 度量(Metrics):对实时大量数据进行计算;
- 事件(Event):支持任意的事件数据,换句话说,任意事件的数据我们都可以做操作。
同时,它有以下几大特点: • schemaless(无结构),可以是任意数量的列; • min, max, sum, count, mean, median 一系列函数,方便统计; • Native HTTP API, 内置http支持,使用http读写; • Powerful Query Language 类似sql; • Built-in Explorer 自带管理工具。
influxdb的两个http端口:8083和8086 • port 8083:管理页面端口,访问localhost:8083可以进入你本机的influxdb管理页面; • port 8086:http连接influxdb client端口,一般使用该端口往本机的influxdb读写数据。
grafana
grafana是用于可视化大型测量数据的开源程序,他提供了强大和优雅的方式去创建、共享、浏览数据。dashboard中显示了你不同metric数据源中的数据 • grafana最常用于因特网基础设施和应用分析,但在其他领域也有机会用到,比如:工业传感器、家庭自动化、过程控制等等。 • grafana有热插拔控制面板和可扩展的数据源,目前已经支持Graphite、InfluxDB、OpenTSDB、Elasticsearch。
Grafana是什么呢?该项目你可能没听过,也比较年轻,他一般是和一些时间序列数据库进行配合来展示数据的,例如:Graphite、OpenTSDB、InfluxDB等
Heapster系统部署
Heapster以InfluxDB作为数据存储后端,再配合Grafana的前端进行数据可视化的系统监控方案,进行部署。
首先,我们在github中搜索Heapster,会找到Kubernetes中的Heapster库
 地址:https://github.com/kubernetes/heapster/releases
地址:https://github.com/kubernetes/heapster/releases
安装Heapster仅需要将yaml文件下载下来即可,但是github不允许下载单个问题,我们这里已经将yaml文件及镜像上传到百度云,直接下载就可以使用。
云盘下载 密码:dghh
下载源码包
wget https://github.com/kubernetes/heapster/archive/v1.5.4.zip
unzip v1.5.4.zip
拷贝Yaml文件
mkdir /root/heapster -p && cp ./heapster-1.5.4/deploy/kube-config/influxdb/* /root/heapster
cp ./heapster-1.5.4/deploy/kube-config/rbac/heapster-rbac.yaml /root/heapster/
当前Yaml文件如下
上传镜像(node节点)
gcr.io_google_containers_heapster-amd64_v1.4.2.tar
gcr.io_google_containers_heapster-grafana-amd64_v4.4.3.tar
gcr.io_google_containers_heapster-influxdb-amd64_v1.3.3.tar
docker load -I [以上镜像]

提示:如果我们不用grafana界面和influxdb,只是为了支持dashboard我们可以只安装rbac和heapster,后面我也没有使用ui界面,所以后面的grafana和influxdb我们可以不安装执行哦~
创建rbac文件
kubectl create -f heapster-rbac.yaml
创建heapster
kubectl create -f heapster.yaml
#需要修改镜像版本,对应yaml文件里的image
创建grafana
kubectl create -f grafana.yaml
#需要修改镜像版本,对应yaml文件里的image
创建influxdb
kubectl create -f influxdb.yaml
influxdb 官方建议使用命令行或 HTTP API 接口来查询数据库,从 v1.1.0 版本开始默认关闭 admin UI,将在后续版本中移除 admin UI 插件。 开启镜像中 admin UI的办法如下:先导出镜像中的 influxdb 配置文件,开启 admin 插件后,再将配置文件内容写入 ConfigMap,最后挂载到镜像中,达到覆盖原始配置的目的:
详细地址: https://jimmysong.io/kubernetes-handbook/practice/heapster-addon-installation.html
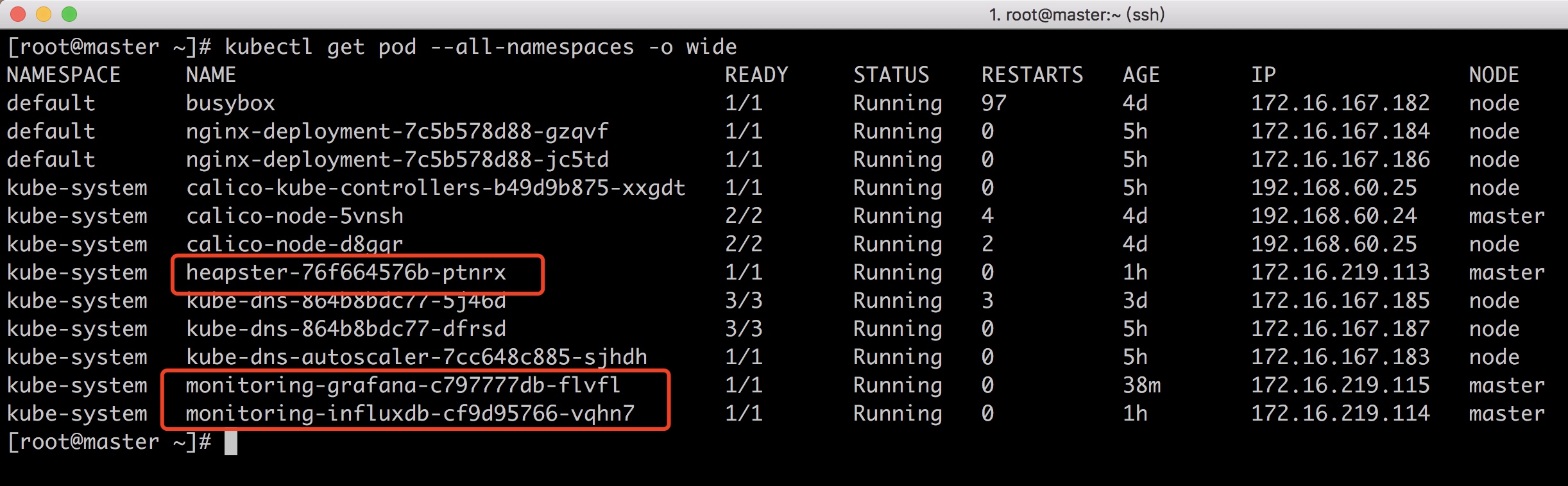
检查
查看pod
查看deployments

测试,查看是否可以获取到值
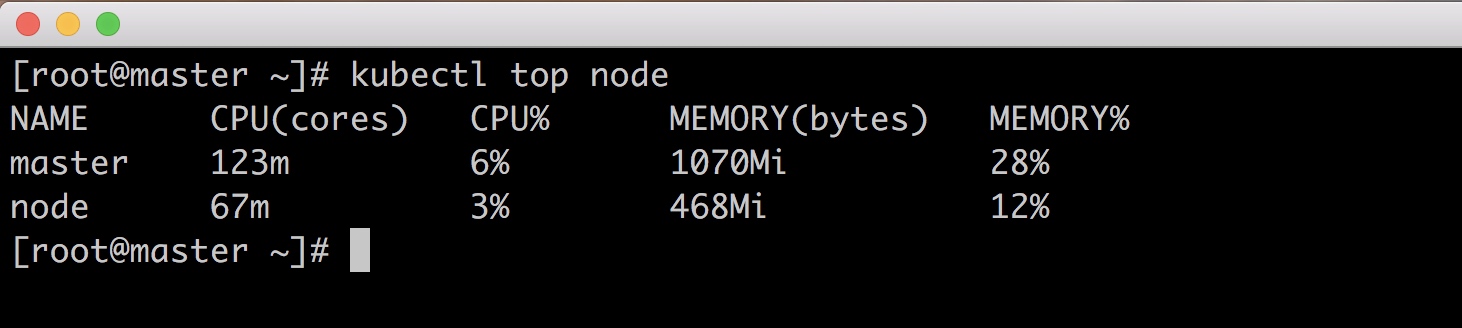
提示:因为Heapster已经被启用,我们这里只是简单介绍,后续会介绍其他监控方案