Kubernetes Ceph 安装
Ceph Install
环境说明
| IP | 服务 | 主机名 | 备注 |
|---|---|---|---|
| 192.168.60.28 | Ceph、Ceph-deploy、Mon | admin-node | mon节点又称为master节点 |
| 192.168.60.29 | Ceph | ceph01 | osd |
| 192.168.60.31 | Ceph | Ceph02 | osd |
Ceph 版本 10.2.11 Ceph-deploy 版本 1.5.39 系统版本 7.4.1708 内核版本 3.10.0-693.el7.x86_64
1.环境准备 三台服务器共同操作
1.关闭selinux && iptables
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i '/SELINUX/s/enforcing/disabled/' /etc/selinux/config
setenforce 0
2.设置时间同步
yum -y install ntp
systemctl enable ntpd
systemctl start ntpd
ntpdate -u cn.pool.ntp.org
hwclock --systohc
timedatectl set-timezone Asia/Shanghai
3.修改主机名 && host
hostnamectl set-hostname [ admin-node | ceph1 | ceph2 ]
hostnamectl set-hostname admin-node
hostnamectl set-hostname ceph1
hostnamectl set-hostname ceph2
echo "192.168.60.28 admin-node" >>/etc/hosts
echo "192.168.60.29 ceph1" >>/etc/hosts
echo "192.168.60.31 ceph2" >>/etc/hosts
bash
4.设置Yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum clean all && yum makecache
Ceph相关设置
安装openssh
yum install openssh-server -y
设置ceph yum源
cat > /etc/yum.repos.d/ceph.repo <<EOF
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/
gpgcheck=0
[ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/
gpgcheck=0
EOF
#all-缓存yum源
yum clean all && yum makecache
配置ceph-deploy部署的无密码登录每个ceph节点 正因为 ceph-deploy 不支持输入密码,你必须在管理节点上生成 SSH 密钥并把其公钥分发到各 Ceph 节点。 ceph-deploy 会尝试给初始 monitors 生成 SSH 密钥对。
在每个Ceph节点上安装一个SSH服务器
yum install openssh-server -y
配置master管理节点与每个Ceph节点无密码的SSH访问。
复制admin-node节点的秘钥到每个ceph节点
ssh-keygen
ssh-copy-id root@admin-node
ssh-copy-id root@ceph1
ssh-copy-id root@ceph2
##测试每台ceph节点不用密码是否可以登录
修改 ceph-deploy 管理节点上的 ~/.ssh/config 文件,这样 ceph-deploy 就能用你所建的用户名登录 Ceph 节点了,而无需每次执行 ceph-deploy 都要指定 --username {username}。这样做同时也简化了 ssh 和 scp 的用法。把 {username}替换成你创建的用户名。
[root@admin-node ~]# vim ~/.ssh/config
### 这里我们不使用普通用户###
[root@admin-node ~]# cat ~/.ssh/config
Host admin-node
Hostname admin-node
User root
Host ceph1
Hostname ceph1
User root
Host ceph2
Hostname ceph2
User root
#填写主机名和用户
设置Yum源,前面已经设置过,这里其实可以忽略
cat > /etc/yum.repos.d/ceph.repo <<EOF
[ceph]
name=ceph
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/x86_64/
gpgcheck=0
[ceph-noarch]
name=cephnoarch
baseurl=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/noarch/
gpgcheck=0
EOF
用ceph-deploy工具部署ceph集群
在master节点上新建一个ceph集群
ceph-deploy用来管理三个节点
yum install -y ceph ceph-deploy
在ceph1节点 & ceph2节点 安装ceph
yum install ceph -y
需要在k8s环境中的master和node节点中安装ceph,用于资源调用存储,只需要安装Ceph,不需要进行认证~
yum install ceph -y
后期如果想使用storageclass模式,需要在K8S中的master节点安装ceph-common,否则会报错
测试ceph是否安装完成
[root@admin-node ~]# ceph --version
ceph version 10.2.11 (e4b061b47f07f583c92a050d9e84b1813a35671e)
[root@ceph2 ~]# ceph --version
ceph version 10.2.11 (e4b061b47f07f583c92a050d9e84b1813a35671e)
[root@admin-node ~]# ceph-deploy --version
1.5.39
在master节点创建monitor
# cd /etc/ceph/
$ ceph-deploy new admin-node
(执行这条命令后admin-node作为了monitor节点,如果想多个mon节点可以实现互备,需要加上其他节点并且节点需要安装ceph-deploy)
ceph-deploy install ceph01 ceph02 --repo-url=http://mirrors.aliyun.com/ceph/rpm-jewel/el7/ 自动部署node节点,不执行这个的话,后面k8s无法调用rbd模块,注意这里,如果上面已经通过yum安装过ceph的,可以不用执行这个-------------
查看ceph.conf 当执行完创建后,会在当前目录下生产ceph.conf
[root@admin-node ceph]# cat ceph.conf
[global]
fsid = 135dc368-9a2f-4943-8d5d-7eb6675808b1
mon_initial_members = ceph1, ceph2
mon_host = 192.168.60.28 #这里应该只有mon节点的IP
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd pool default size = 2
rbd_default_features = 1
osd journal size = 2000
### 添加后面3行,解释如下
ceph.conf配置文件修改
设置默认副本数为2份,有一个副本故障,其他3个副本的osd可正常提供读写服务,需要注意的是如果设置为副本数为2,osd总数量需要是2的倍数
# echo "osd pool default size = 2" >> ceph.conf
增加 rbd_default_features 配置可以永久的改变默认值。注意:这种方式设置是永久性的,要注意在集群各个 node 上都要修改。
增加配置默认 feature 为 layering 对应的bit码整数值 1
#echo "rbd_default_features = 1" >> ceph.conf
要设置Ceph的网络配置,您必须添加一个网络配置在配置文件在[global ]部分。我们5分钟的快速启动提供了一个简单的Ceph的配置文件,假设一个公网客户端和服务器上相同的网络和子网。 Ceph的功能仅对一个公共的网络起作用。然而, Ceph可以建立更具体的标准,其中包括多个IP网络和公共网络的子网。您也可以建立单独的集群网络处理OSD心跳,对象备份和故障恢复。不要混淆IP您在您的配置设置面向公众的IP地址的网络客户端的IP地址,可以使用它来访问您的服务。典型的内部IP网络往往是192.168.0.0 10.0.0.0 。
提示:如果您指定一个以上的IP地址和子网掩码,无论是公共或群集网络的子网内的网络必须能够路由到对方。此外,请确保您包括您的IP为他们必要的表和开放端口的每一个IP地址/子网。
注意:Ceph使用CIDR表示法的子网(例如, 10.0.0.0/24 ) 。
当你配置你的网络,你可能会重新启动您的群集或重新启动每个守护进程。 Ceph的守护程序动态绑定,所以你不必重新启动整个集群一次,如果你改变你的网络配置。
PUBLIC NETWORK
# echo "public network = 10.0.0.0/16" >>ceph.conf
OSD日志大小(MB)
# echo "osd journal size = 2000 " >>ceph.conf
查看文件格式
df -T -h|grep -v var
注意,如果是ext4的文件格式需要执行下面两个命令,在创建集群之后
echo "osd max object name len = 256" >> ceph.conf
echo "osd max object namespace len = 64" >> ceph.conf
master节点初始化mon节点及收集密钥信息
# ceph-deploy mon create-initial
[ceph_deploy.conf][DEBUG ] found configuration file at: /root/.cephdeploy.conf
[ceph_deploy.cli][INFO ] Invoked (1.5.39): /usr/bin/ceph-deploy mon create-initial
[ceph_deploy.cli][INFO ] ceph-deploy options:
[ceph_deploy.cli][INFO ] username : None
[ceph_deploy.cli][INFO ] verbose : False
[ceph_deploy.cli][INFO ] overwrite_conf : False
[ceph_deploy.cli][INFO ] subcommand : create-initial
[ceph_deploy.cli][INFO ] quiet : False
[ceph_deploy.cli][INFO ] cd_conf : <ceph_deploy.conf.cephdeploy.Conf instance at 0xbf7d40>
[ceph_deploy.cli][INFO ] cluster : ceph
[ceph_deploy.cli][INFO ] func : <function mon at 0xbf05f0>
[ceph_deploy.cli][INFO ] ceph_conf : None
[ceph_deploy.cli][INFO ] default_release : False
[ceph_deploy.cli][INFO ] keyrings : None
[ceph_deploy.mon][DEBUG ] Deploying mon, cluster ceph hosts admin-node ceph1 ceph2
[ceph_deploy.mon][DEBUG ] detecting platform for host admin-node ...
[admin-node][DEBUG ] connected to host: admin-node
#############省略部分
mon. --keyring=/var/lib/ceph/mon/ceph-admin-node/keyring auth get client.bootstrap-osd
[admin-node][INFO ] Running command: /usr/bin/ceph --connect-timeout=25 --cluster=ceph --name mon. --keyring=/var/lib/ceph/mon/ceph-admin-node/keyring auth get client.bootstrap-rgw
[ceph_deploy.gatherkeys][INFO ] keyring 'ceph.client.admin.keyring' already exists
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mds.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-mgr.keyring
[ceph_deploy.gatherkeys][INFO ] keyring 'ceph.mon.keyring' already exists
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-osd.keyring
[ceph_deploy.gatherkeys][INFO ] Storing ceph.bootstrap-rgw.keyring
[ceph_deploy.gatherkeys][INFO ] Destroy temp directory /tmp/tmpHhcN8i
admin-node把配置文件和admin密钥分发到各个节点,仅仅需要分发给mon节点即可 ceph-deploy admin admin-node 我们的admin-node和mon在一起,我们就发送给admin-node(这步不操作也可以)
创建osd的目录并激活 osd上需要建立对应的目录-用户存储数据
mkdir -p /ceph && chown -R ceph.ceph /ceph/
#这里的目录我们可以添加一块磁盘或者直接创建目录挂载
我们这里演示添加一块硬盘
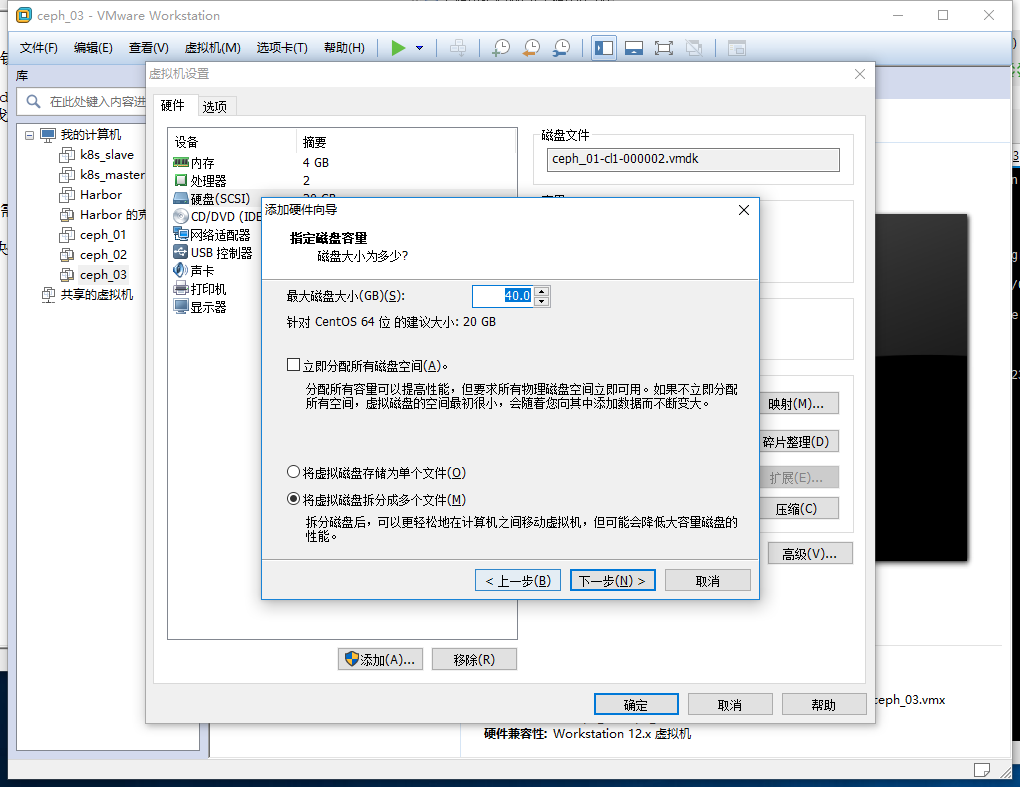 我们需要将三台服务器都添加一块40G的硬盘
我们需要将三台服务器都添加一块40G的硬盘
[root@ceph1 ~]# ll /dev/sd*
brw-rw---- 1 root disk 8, 0 Aug 13 10:25 /dev/sda
brw-rw---- 1 root disk 8, 1 Aug 13 10:25 /dev/sda1
brw-rw---- 1 root disk 8, 2 Aug 13 10:25 /dev/sda2
brw-rw---- 1 root disk 8, 16 Aug 13 10:25 /dev/sdb
执行 fdisk /dev/sdb 对磁盘分区,需要依次输入 “n” ,"p","1",两次回车 "wq"
[root@ceph1 ~]# fdisk /dev/sdb
Welcome to fdisk (util-linux 2.23.2).
Changes will remain in memory only, until you decide to write them.
Be careful before using the write command.
Device does not contain a recognized partition table
Building a new DOS disklabel with disk identifier 0xb88b7dd5.
Command (m for help): p
Disk /dev/sdb: 42.9 GB, 42949672960 bytes, 83886080 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xb88b7dd5
Device Boot Start End Blocks Id System
Command (m for help): n
Partition type:
p primary (0 primary, 0 extended, 4 free)
e extended
Select (default p): p
Partition number (1-4, default 1): 1
First sector (2048-83886079, default 2048):
Using default value 2048
Last sector, +sectors or +size{K,M,G} (2048-83886079, default 83886079):
Using default value 83886079
Partition 1 of type Linux and of size 40 GiB is set
Command (m for help): wq
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
完毕后执行 fdisk -l 即可看到已经分区的磁盘,并记住盘符标识我们这里是/dev/sdb1
[root@ceph1 ~]# fdisk -l
Disk /dev/sdb: 42.9 GB, 42949672960 bytes, 83886080 sectors
Units = sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk label type: dos
Disk identifier: 0xb88b7dd5
Device Boot Start End Blocks Id System
/dev/sdb1 2048 83886079 41942016 83 Linux
格式化分区
[root@ceph1 ~]# mkfs.xfs /dev/sdb1
meta-data=/dev/sdb1 isize=512 agcount=4, agsize=2621376 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=10485504, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=5119, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
添加到/etc/fstab
[root@ceph1 ~]# echo '/dev/sdb1 /ceph xfs defaults 0 0' >> /etc/fstab
[root@ceph1 ~]# mount -a
mount: mount point /ceph does not exist
[root@ceph1 ~]# mkdir /ceph
[root@ceph1 ~]# mount -a
其他服务器也按照相同的操作
[root@ceph1 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 17G 1.7G 16G 10% /
devtmpfs 1.9G 0 1.9G 0% /dev
tmpfs 1.9G 0 1.9G 0% /dev/shm
tmpfs 1.9G 8.6M 1.9G 1% /run
tmpfs 1.9G 0 1.9G 0% /sys/fs/cgroup
/dev/sda1 1014M 143M 872M 15% /boot
tmpfs 378M 0 378M 0% /run/user/0
/dev/sdb1 40G 33M 40G 1% /ceph
三台服务器同时执行
chown -R ceph.ceph /ceph/
在master节点创建osd:
cd /etc/ceph/
ceph-deploy osd prepare admin-node:/ceph ceph1:/ceph ceph2:/ceph
激活osd
ceph-deploy osd activate admin-node:/ceph ceph1:/ceph ceph2:/ceph
master创建mon节点-监控集群状态-同时管理集群及msd
ceph-deploy mon create admin-node
如果需要管理集群节点需要在node 节点安装ceph-deploy,因为ceph-deploy是管理ceph节点的工具
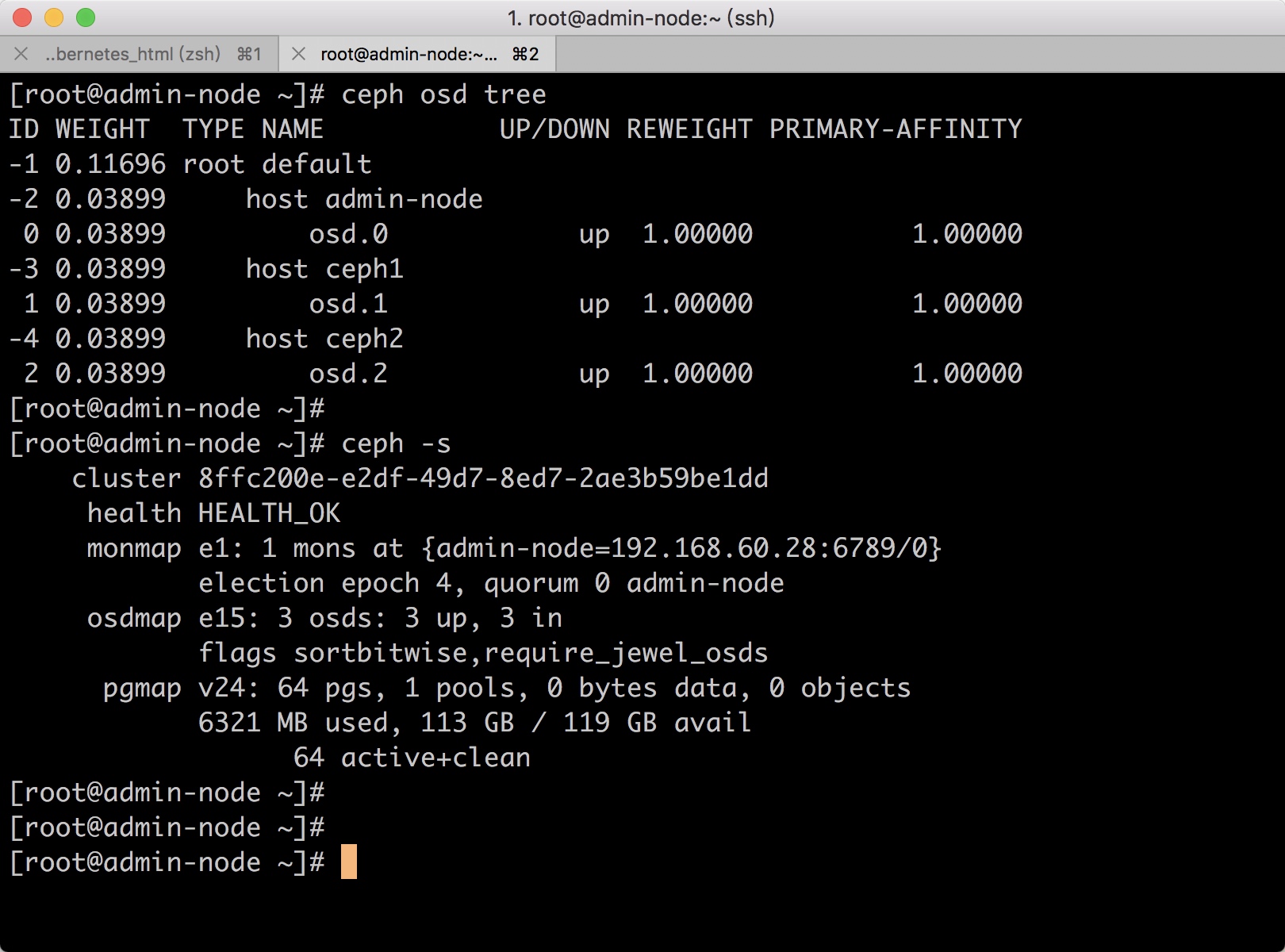
查看osd节点状态
[root@admin-node ceph]# ceph -s
cluster 96a28dc8-9907-4f42-b15b-a22de899d14d
health HEALTH_OK
monmap e1: 3 mons at {admin-node=192.168.60.28:6789/0,ceph1=192.168.60.29:6789/0,ceph2=192.168.60.31:6789/0}
election epoch 12, quorum 0,1,2 admin-node,ceph1,ceph2
osdmap e15: 3 osds: 3 up, 3 in
flags sortbitwise,require_jewel_osds
pgmap v23: 64 pgs, 1 pools, 0 bytes data, 0 objects
6321 MB used, 113 GB / 119 GB avail
64 active+clean
查看ceph集群磁盘
[root@admin-node ceph]# ceph df
GLOBAL:
SIZE AVAIL RAW USED %RAW USED
119G 113G 6321M 5.15
POOLS:
NAME ID USED %USED MAX AVAIL OBJECTS
rbd 0 0 0 55177M 0
我们3台服务器每台硬盘40G组成的120G
#附加:添加其他的mon机器------------------------ ceph-deploy mon add 主机名
#查看osd的节点状态
ceph osd tree
ceph -s
#查看osd的状态-负责数据存放的位置
ceph-deploy osd list admin-node ceph1 ceph2
#查看集群mon选举状态
ceph quorum_status --format json-pretty